{kind=link}
Background
In my last post I wrote Why I became an Educator I was bemoaning the lack of focus on Low Level understanding that seems to have afflicted Computer Science degree courses of recent times (at least in the UK…).
As a result, I received a comment from someone called Travis Woodward that said:
There are plenty of students out there who are more than willing to dive into low level stuff, but its hard to know where to start or even what to learn (the old ‘you don’t know what you don’t know’ problem).
I’ve looked around for something approaching a low level curriculum, but they tend to just be lists of topics which aren’t actually that helpful without context and suggested resources to start you off. The best intro I’ve found so far is a course called CS107: Programming Paradigms from Stanford on iTunesU, which has a good section on how C and C++ look to a compiler.
So if any low level programmers want to put together a low level curriculum with suggested resources, then please do! :)
This is of course a commendable idea, and so I decided to get started on it…
Low Level Curriculum?
Before I go any further, I’d like to clarify what I mean by “Low Level Curriculum”.
During my time in the industry I’ve helped architect and build a multi-platform once-Next-Gen-now-current-gen engine and tool chain, I’ve written plenty of shaders, tracked down countless hideous bugs by looking at disassembly and memory windows, hunted down the odd submission blocking threaded race condition, and on several occasions had to hand-unpick the broken stacks of core dumps from PS3 / X360 test decks to find bugs that only occur “in the wild”; but that doesn’t make me a low level programmer – this is the kind of thing I’d expect anyone with my sort of experience to have done.
I’ve never sat for hours poring over GPad or Pix captures, I’ve never really had to worry about stuff like patching fragment shaders or batched physics calculations on SPUs, or how to get the most from my AltiVecs, and I’ve certainly never had to re-code large chunks of code in assembler taking advantage of caching or sneaky DMA modes to get a few extra FPS out of anything – this is what low level programmers do, platform specific hardware optimised code usually written to get the best performance out of a machine.
This curriculum is not about learning to be a low level programmer.
What it is about is gaining a solid understanding of the low level implementational underpinnings of C and C++ * – an understanding that I strongly feel should be the base line for any programmer working in games.
Over the course of however many posts this eventually takes up I’ll be covering:
- Data types
- Pointers, Arrays, and References
- Functions and the Stack
- The C++ object model (several posts)
- Memory (again, several posts)
- Caches
Assuming you read and understand all of the posts in this series – and that I manage to communicate the information effectively – you should end up in a place where for any given “foible” of the language you understand not only that it exists but also – and most crucially – why it exists.
For example, you may (or may not) know that virtual function calls don’t work in constructors, before the end of this series of posts you will understand why they can’t work in constructors.
Again just to be clear, I’m not necessarily talking about the same level of understanding of this as someone who writes compilers for their day job; but certainly a level of understanding that gives you a much better idea of what is likely to be going on at the level of the underlying engine that C++ sits on top of, and which consequently enables you to far better understand the implications of the code you write.
* N.B. to be 100% clear, C will be covered strictly as a subset of C++.
There is no source code available for the current location.

Aieeee! Spare me the hexadecimal!
I’m sure the vast majority of programmers who use Visual Studio freak out the first few times they see this dialog.
I know I did.
I learned to program primarily in a green (or orange if the green screens were taken) screen dumb terminal Unix mainframe environment. You know, like they have in old films like Alien. The second and third year students had priority use of the XWindows machines (and the few Silicon Graphics workstations were for 3rd year graphics projects only), so dumb terminals were where I learned my trade.
Even on the XWindows machines there was no programming IDE that I was aware of – I used EMACS and GNU make files, and the only debugger I had use of was command line GDB, which is not what you’d call user-friendly. I got by with std::cout.
When I graduated I went from this world of bakelite keyboards, screen burn, and command lines into the bright world of windows 95 development using Visual Studio 4 (slightly before Direct X and hardware accelerated graphics).
When I first saw this dialog box you can bet your life I freaked out – and why wouldn’t I?
Thanks to the language syntax and code architecture focussed high level teaching methods employed by my university I had no more idea of what went on behind the veil of the compiler than my brief forays into debugging with GDB had afforded me.
I’d just got a degree from a well-respected University where they had altogether avoided teaching me about assembler as part of the main syllabus, and I had assumed it was because they were worried it was too much for my puny mind to deal with.
Suffice to say, I got over the freaking out part – but I still saw this dialog as a “No Entry” sign for far longer than I’d like to admit.
I only really started to really get over it a few years later when I was working closely with someone who had got a job in games on the strength of their assembler programming.
I had a crash, and they just casually leant over and clicked the “Show Disassembly” button. Then, equally casually, showed me exactly why my code was crashing – explaining it in terms of how C++ maps to assembler – and told me how to fix it.
This blew my mindgaskets three times because:
- this person was so casual about it
- disassembly clearly wasn’t the black magic it appeared to be
- given it was so simple I couldn’t believe I hadn’t been taught about the low level innards of C++ at University
Rending the Veil of Disassembly
I really didn’t realise how incredibly important this was until I had the pleasure of meeting a guy called Andy Yelland. If you already know Andy, then you will know exactly what I mean, but for those of you who have not met him I will explain.
Andy is one of those people who changes your perspective. He is more or less the polar opposite of the stereotypical ninja-level video game programmer: well dressed, professional, endlessly well-informed, friendly, funny, and socially adept.
However, the most amazing thing about Andy is the speed with which he can dissect a console core dump. He just sits there and calmly unpicks the stack, occasionally keeping a few notes about which register some value is in, or looking up the address of a function in a symbol file as he goes, and then in somewhere between 5 minutes and a few hours (depending on how tricky the issue is) he’ll turn around and tell you exactly what the problem was.
Not only that, but he’ll happily do this in a codebase he’s never even seen before – and even better, he’s totally happy to sit and explain it all to you as he does it.
After sitting with Andy for a few dissections I realised that whilst what he does seems like black magic, it is in fact anything but.
It’s about having an expert understanding of how C++ works at the assembly level, and bloody-mindedly applying that knowledge to reverse engineer the state of the system backwards from the current stack state (i.e. when the crash happened) to the point where the bad data was introduced.
Clearly this takes a lot of practice, and to get anywhere near as good as Andy at it will take anyone (who isn’t Rain Man) years of their life.
I’m not saying that I think everyone should be able to casually decipher disassembly representing code they didn’t write – I certainly can’t do that.
What I am saying is that I think all game programmers should be able to look at disassembly and be able to at least make an educated guess at what is going on, and by leveraging their understanding of how C++ is implemented at the low level – and given time, possibly with some hardware manuals – then they should be able to work it out.
The first rule of the Low Level Curriculum for C++: Don’t fear Disassembly
Ok, so assuming that you agree with me where do you start?
I think the best way to start making sense of it is to look at some simple code in the disassembly window, so let’s do that.
Make yourself a test project in a C++ programming IDE of your choice and write some simple code in your main() function.
For the sake of argument, let’s say you’re using my weapon of choice – Visual Studio 2010 on a Windows PC.
The Code I’m suggesting we look at is this:
1 2 3 4 5 | int x = 1; int y = 2; int z = 0; z = x + y; |
Make sure you’re in the “debug” configuration, and put a breakpoint on the line
z = x + y;
then run the program.
When the breakpoint gets hit, right-click in the text editor and choose “Go To Disassembly” from the context menu.
DON’T PANIC!
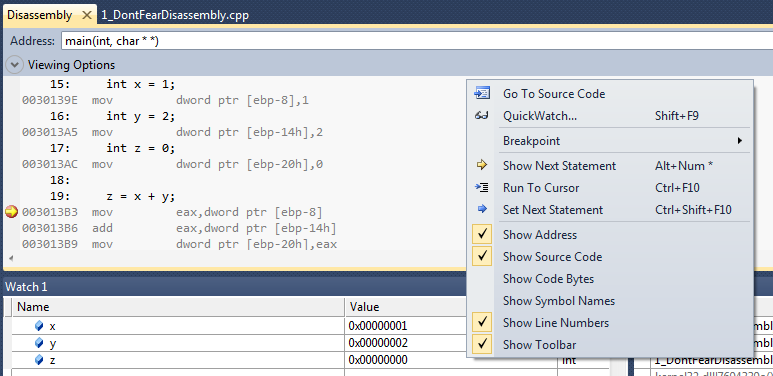
NOTE: ensure that you have the same options checked in the right-click context menu!
You should now see something that looks something like the image above. Your text will almost certainly be scrolled differently, because I’ve messed about with the window sizes and text position for clarity.
The black text with line numbers is clearly the code we compiled, the grey text below each line of code shows the assembler that each line of code generated.
So what does it all mean?
The hexadecimal number at the start of each line of assembler is the memory address of that line of assembler – remember code is really just a stream of data that tells the CPU what to do, so logically it must be at an address in memory. Don’t worry about these too much, I just wanted to make the point that the instructions are in memory too.
mov and add are assembler mnemonics – each represents a CPU instruction, one per line with its arguments.
eax and ebp are two of the registers in the x86 CPU architecture. Registers are “working area” for CPUs: fragments of memory that are built into the CPU itself, and which the CPU can access instantaneously. Rather than having addresses like memory, registers are named in assembler because there are usually only a (relatively) small number of them.
The eax register is a “general purpose” register, but is primarily used for mathematical operations.
The ebp register is the “base pointer” register. In x86 assembler, local variables will typically be accessed via an offset from this register. We will cover the purpose of ebp in later posts.
As I alluded to in the previous sentence, ebp-8, ebp-14h, and ebp-20h are the memory addresses (as offsets from the ebp register) storing the values of the local variables x, y, and z respectively.
dword ptr [ ... ] means “the 32 bit value stored in the address in the square brackets” (this is definitely true for the Win32 assembler, it may be different for the Win64 one – I’ve not checked).
How does it work?
Now, we know that the assembler generated by the C++ code we’ve written will initialise the three variables x, y, and z; then add x to y and store the result in z.
Let’s look at each line of assembler in isolation (ignoring the address).
mov dword ptr [ebp-8],1 |
This assembler instruction sets the value of the variable x by moving the value 1 into the memory at address ebp-8.
mov dword ptr [ebp-14h],2 |
This assembler instruction sets the value of the variable y by moving the value 2 into the memory at address ebp-14h – n.b. the ‘h’ is necessary because 14 in decimal is a different value from 14 in hexadecimal – this wasn’t necessary when specifying the offset for the value of x because 8 is the same value in decimal and hexadecimal.
mov dword ptr [ebp-20h],0 |
This instruction is, unsurprisingly, setting the value of the variable z.
Now we’re up to the interesting part, doing the arithmetic and assigning the result to z.
mov eax, dword ptr [ebp-8] |
This instruction moves the value of the memory at address ebp-8 (i.e. x) into the eax register…
add eax, dword ptr [ebp-14h] |
…this instruction adds the value of the memory at address ebp-14h (i.e. y) to the eax register…
mov dword ptr [ebp-20h],eax |
…and this instruction moves the value from eax into the memory at address ebp-20h (i.e. z).
So, as you can see, whilst the assembler looks very different, it is logically isomorphic with the C++ code that it was generated from (i.e. whilst its behaviour may be slightly different, it will give the same output for any given input).
Hold on, why did we look at that again?
Those of you with brains connected to your eyes will have noticed that the intro to disassembly I just gave was – to use a British colloquialism – “a bit noddy”.
In all honesty, that was the whole point of choosing such a simple example. the intention was to show how something as simple as adding two integers and storing the result in a third in C++ maps to assembler.
You can use this exact technique to look at the vast majority of the C++ language constructs and see what they actually generate, and the purpose of this was to show you that it’s simple enough to do.
Obviously this example showed only two of the x86 assembler mnemonics, of which there are many more.
If you want to make sense of assembler code that is using mnemonics you don’t know, it’s usually as simple as googling them. That’s all I’ve ever done, and there is so much information about x86 assembler floating about on the interweb that you should have little trouble deciphering it.
I found a super helpful webpage that covers the x86 registers in some detail: http://www.swansontec.com/sregisters.html
Here’s a link to a page to download a .pdf x86 “cheat sheet”: http://www.jegerlehner.ch/intel/
And the obvious wikipedia page: http://en.wikipedia.org/wiki/X86_instruction_listings
And a beefy link also linked from wikipedia: http://home.comcast.net/~fbui/intel.html
Summary
Whilst very few programmers will ever need to write assembler, all game programmers will – sooner or later – find it to their advantage to be able to read and make some sense of it. It’s amazing what you can figure out with only a partial knowledge of assembler and how it maps to C++ code.
The example code we looked at was, as I’ve already admitted, very simple.
The point of this first post wasn’t to give you answers, but to show that the disassembly window is only daunting if you let it be; and to encourage you to explore what your compiler is doing with the code you give it.
Don’t give up just because you don’t understand what you’re seeing yet; google it or post a specific question somewhere like http://stackoverflow.com/.
Epilogue
I guess there are a few other things that I’d like to draw your attention to a few other things that I think are there to take away from this tiny snippet of disassembly:
- the C++ concept of a variable (or any other language’s concept of a variable for that matter) doesn’t exist at the assembler level. In assembler the values of x, y, and z are stored in specific memory addresses, and the CPU gets at them by explicit use of their respective memory addresses. The high level language concept of a variable, whilst easier to think about, is actually already an abstracted concept identifying a value in a memory address.
- note that in order to do anything “interesting” (e.g. add a value to another) the CPU needs to have at least part of the data it is operating on in a register (I’m sure some that some CPUs must be able to operate directly on memory, but it’s certainly not the usual way of doing things).
Finally, I feel that this extremely simple example illustrates what I think is one of the most important facts about programming:
High level languages exist only to make life easy for humans, they’re not any kind of accurate reflection of how CPUs actually work – in fact even assembler is a human convenience compared to the actual binary opcodes that the mnemonics (e.g. mov, add etc.) represent.
My advice is don’t think about the actual opcodes too much, and definitely don’t worry about the electrons or the silicon :)