{kind=link}
Behavior Tree Entrails
Today I peek at the main data structures forming my behavior tree runtime implementation and their interplay during the update of a behavior tree controlled agent.
Data-oriented behavior tree series
This article is part of a series of blog posts about my data-oriented behavior tree experiment:
- Introduction to Behavior Trees
- Shocker: Naive Object-Oriented Behavior Tree Isn’t Data-Oriented
- Data-Oriented Streams Spring Behavior Trees
- Data-Oriented Behavior Tree Overview
- Behavior Tree Entrails (this text)
Oh – it is full of data!
In the last installment of this blog series I depicted the central ideas behind my data-oriented behavior tree approach. My central experimentation idea is to minimize the memory necessary to store and process behavior trees and to make it easy (unproven yet) to stream data to the local cache or storage of the deployed compute units.
My implementation is based on three main data structures:
- the shape or gestalt of a behavior tree,
- an agent’s behavior execution state, e.g., which actions are running, stored in a so called actor data structure,
- interpreter data used to buffer new states generated while updating a behavior tree by processing an agent’s shape and actor data.
Shape of a behavior tree
A shape describes the static structure of a behavior tree. The behavior tree is flattened into a one dimensional array or stream. Array elements are shape items which represent tree nodes.
Shape items are differentiated by their type. Inner nodes a.k.a. branches are deciders which decide when to run which of their children. Therefore, deciders steer behavior tree traversal. Leaf nodes and their shape items are actions (persistent, immediate, or deferred).
Currently all shape items are 64bit in size and contain a type field and a union for the data of different node types. I’m pondering if to cut that down to 32bit and then use multiple items if necessary to represent a node, or, alternatively, to adopt a binary blob design as described by Niklas Frykholm in his AltDevBlogADay (ADBAD) post Managing Decoupling Part 3 – C++ Duck Typing.
A shape data structure references:
- its shape item stream,
- an array of shape item indices whose positions mirror persistent states stored in actor data structures (see below) and therefore create a mapping between an agent’s persistent states and the shape item they supply the state for,
- a specification spelling out the capacity of the state buffers of actors and interpreters.
Actor – execution state
Multiple agents might share the same behavior tree shape but as each has an individual world view their behavior execution states differ from each other.
An actor data structure consists out of:
- running execution states of immediate and deferred actions, and termination states of previously running deferred actions,
- the decider states of the last update tick,
- all persistent states of the agent, including persistent action states,
- a reference to the agent’s blackboard.
Action states encode the behavior or execution state of an action (ready, running, success, fail). The action is identified by the index of the associated shape item in the shape item stream. To save memory, only non-default states are stored.
When a game system completes execution of a deferred action for an agent, it changes the actor’s running action state to the termination state so the interpretation process can react to the change (event) during the next update.
Decider states contain the non-default traversal state of a decider from the previous update and connect it to the decider’s shape item via an index. For example, sequence decider states carry the last running child shape item index to enable the sequence to pick up traversal from it.
Persistent states belong to shape items representing persistent actions or decorators with timers or counters.
All states are stored in increasing order of their shape item indices. This aligns the order in which shape items and their states are iterated during an update tick.
Currently, each kind of state has its own fixed-bit-sized data structure but I might split this to store the shape item indices and the data separately to save memory and to unify the code for searching and sorting shape item states.
An agent’s blackboard aggregates all agent specific game world knowledge. It’s the only data immediate action functions are allowed to access to keep cache misses at bay. A blackboard data structure might just be a C struct with fields like used by blob that’s easily kept or streamed into local memory/cache.
Interpreter data
The update process itself facilitates an interpreter data structure to collect the next action and decider states and requests to launch or cancel deferred actions. It also contains buffers for persistent state changes.
Furthermore, the interpreter maintains indices for its reading position in the behavior shape item stream and in the decider, action, and persistent state buffers of the interpreted actor.
An interpreter contains a cancellation token. It represents the range of shape items that need to be explicitly cancelled or deactivated if a higher-up decider abandons previously running sub-behaviors and their active actions.
Last but not least, a stack for so called decider guards is used to capture the current traversal location in the behavior tree hierarchy. The stack’s top decider guard represents the parent decider of the currently ticked shape item and handles the traversal semantics for the decider node it’s associated with.
Each decider guard stores:
- the shape item index of its decider,
- its decider’s type,
- the index of the first shape item behind the guarded decider sub-stream to detect if the next shape item to visit still belongs to the decider’s sub-tree,
- an index for the last reached child, e.g., to enable a sequence to store and then return to a running sub-behavior in the next update,
- indices to roll back the interpreter’s decider state, persistent state changes, and action launch request buffers in case of cancellation to reset the buffers to the state before entering the guarded decider,
- concurrent decider guards store an “aggregated state” so a running child turns the whole concurrent decider into a running state as long as no child fails.
Interpreting shapes and actor’s for glorious, errr, decision making and action execution scheduling
When looking at the shape items and the actor states as streams of instructions and data which are processed by using the interpreter buffers, then the interpretation itself can be understood as a virtual machine (VM) or a kernel.
Before the update of an agent’s decision making and action scheduling process starts, the deferred action execution state updates from the different game systems are collected and used to update the stored deferred action states in the agent’s actor data. Afterwards, an edit stage might change the shape stream and adapt the stored states shape item indices accordingly (and shouldn’t forget to tell game systems that run deferred actions about the shape item index changes, too).
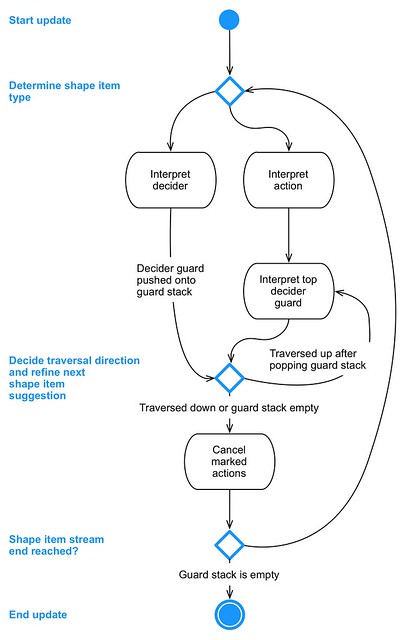
To tick an agent’s update, the interpreter is called with the interpreter, shape, and actor data. Additionally, an array of functions to call for immediate actions, and a buffer to store deferred action and launch requests from all actors is passed to the interpreter function. It then iterates over the shape item stream and for each selected shape item runs through the following steps:
- 1. Interpret the shape item by executing an item type specific function with the determined state.
- 2. Determine the next shape item to interpret:
- 2.1. If the decider guard stack is empty goto 3.
- 2.2. Interpret the top decider guard to refine the next shape item suggestion and the cancellation token.
- 2.3. If the next shape item index is inside the guarded shape item index range, then goto 3., otherwise pop the decider guard stack and goto 2.1.
- 3. Cancel actions, if necessary.
- 4. If the guard stack is not empty, then loop to 1.
- 5. Complete update.
Let’s look at these steps one after the other – an alternative view is also shown in the figure below.
{kind=link}
1. Execute shape item
A shape item type specific function is called to interpret the indexed/selected shape item. It searches the actor state buffers for a state associated with the shape item’s index. If none is found, then a default state is created, e.g., to launch an action or to start a sequence from its first child.
A persistent action simply returns its state as its execution state.
An immediate action shape item is interpreted by calling the indexed function from the immediate action array and by passing the state and the actor’s blackboard to it. If it returns a running execution state, then this state is pushed onto the interpreter’s action state buffer.
Interpretation of a deferred action shape reacts to a ready or launch state by pushing a launch request onto the interpreter’s deferred action request buffer. On receiving a running state it is passed along to the action state buffer of the interpreter. Termination states are simply returned to the interpreter without keeping their state.
After processing an action, the shape item index is incremented by one.
Deciders are handled by pushing a decider guard to handle their traversal semantics onto the interpreter’s decider guard stack. Based on the state the interpreter’s shape item index is advanced to the next sub-behavior to access.
3. Determine the next shape item to interpret
The shape item index stored in the interpreter is merely a suggestion which item to interpret next.
If the last shape item is an action, then the current top of the decider guard stack is interpreted to react to the execution state returned by the action. If the traversal semantics of the guarded decider dictate to leave the decider and traverse up, e.g., because an action below a sequence failed, then the shape item index suggestion is set to the index behind the guarded decider sub-stream and the guard’s execution state is returned to the interpreter, otherwise the shape item index belongs to the next child to traverse down to.
If the refined shape item index is outside the top decider guard’s sub-stream, then the guard stack is popped and the new top guard gets a look at the last execution state and the index suggestion to decide upon further traversal, and so on, and so on.
An empty guard stack signals that traversal left the behavior tree root node upwards – the actor update is done.
Wait, there is more to decider guards – cancellation handling:
- A concurrent decider guard might have processed a few running and some successful sub-behaviors when a child fails. This means, that the whole decider fails and it needs to cancel all running children – the ones it just traversed and the ones not yet reached which have a running state from the previous update.
- When the guard of a priority selector receives a running or success execution state back from a higher priority child than the one which returned a running state during the last update, then it needs to abandon and cancel the previously running lower-priority actions it won’t visit in the current update tick.
In cases like described above a decider guard grows the interpreter’s cancellation range to include the parts of the guarded sub-stream whose actions need cancellation.
A concurrent decider guard rolls the interpreter’s decider state buffer, persistent state change buffer, and the action launch request buffer back to their state before entering the decider. No decider state equals a default state during the next update, persistent state changes won’t be applied, and deferred action launch requests won’t be submitted to their game systems.
3. Cancel actions, if necessary
This step is reached when the decider guard stack is empty or when the traversal does not step up but down in the tree. Stepping down means that new action states might be generated. Before that happens the interpreter’s cancellation range is examined to find out if actions need to be cancelled and therefore their states need to be purged from the interpreter’s action state buffer.
If the cancellation range is not empty, then cancellation happens in two fell swoops:
- If the cancellation range begins before the current shape item index, e.g., because a concurrent decider guard wants to cancel just traversed actions, then all next action states inside that range and stored in the interpreter’s action state buffer are used to call their associated immediate actions with a cancel execution state,s while action cancellation requests are pushed to the interpreter’s action cancellation stack.
- If the cancellation range ends behind the current shape item, then the actor’s action states (states from the previous update) inside that range are cancelled like described above.
When cancellation is done the cancellation range is set to be empty again.
As a priority selector might execute all actions of a high-priority sub-behavior before canceling the previously running, lower-priority actions. The higher-priority actions need to cope with side effects from the not yet cancelled lower-priority actions on the actor’s blackboard.
4. Loop to 1
Just what the step description says. Loop back to step one to interpret the next selected shape item. Nuff said.
5. Complete update
The end is nigh – at least for an agent’s behavior tree update tick.
For this simulation step all decisions have been made and all actions have been ticked or requests for them have been collected. To finish the update tick:
- Sort the interpreter’s next decider state buffer in increasing order of the states shape item indices. This is necessary as decider guards create states for their guarded deciders when they are left while the state needs to be available in the actor’s decider state buffer when the decider is entered during the next execution. The interpreter’s decider states are then used to replace the actor decider states.
- The explicitly emitted persistent state changes are sorted for their shape item indices and then iterated and applied to the actor’s persistent states.
- For each deferred action launch request a running action state is inserted into the interpreter’s next action state buffer. Afterwards the buffer is sorted and then replaces the actor’s action states.
- All of the agent’s collected action launch and cancellation requests are copied to the action request buffer argument passed to the interpreter function.
- The interpreter’s buffers are emptied to prepare for the next agent to interpret (which might possibly even be controlled by a different shape stream).
And the beat goes on
To all who managed to read on until this point: you are awesome! Hurrah for curious and engaged readers! My confession: I cut nearly half of the text I initially wrote to keep this post at a reasonable (?) size.
I haven’t blogged for quite some time because I poured the writing time into coding the described behavior tree implementation and into a system to store and manage multiple shapes and actors. I’m now starting to transfer and clean-up the experimental code into an open source project (BSD type license). Hopefully I can lift the curtain on it this year.
Ok, that’s it for this post. I’m looking forward to your feedback, questions, and comments here, or via Google+ or email.
References
- Niklas Frykholm, Managing Decoupling Part 3 – C++ Duck Typing, 2010.
- The Blob and I, 2010.
- Damien Isla, Handling Complexity in the Halo 2 AI, 2005.
Data-oriented behavior tree series
- Introduction to Behavior Trees
- Shocker: Naive Object-Oriented Behavior Tree Isn’t Data-Oriented
- Data-Oriented Streams Spring Behavior Trees
- Data-Oriented Behavior Tree Overview
- Behavior Tree Entrails (this text)