{kind=link}
Todays episode about my behavior tree experiment crashes you into menacing hardware walls, starts a wild flirt with data-oriented design to soothe the pain, and all of that just because of my nagging problems with a naive object-oriented behavior tree sketch. Oh, and in the dramatic end I’ll interrogate – aeh – ask you questions, too!
Ok, I’ll stop my Hollywood-tinted writing style for now. Time for the hard and merciless truth (oh no, I did it again) about pointers, random memory accesses, and why I want to find a better runtime representation for my behavior trees.
Article Updates
- March 18, 2011 – Posted bjoernknafla.com, too.
Mini recap – behavior trees
This will be a quick overview of behavior trees. Read Introduction to Behavior Trees for a more in-depth overview. Ok, breath in, and go, go, go:
Behavior trees (BTs) are deployed by more and more game AI programmers to implement reactive decision making and control for entities (also called agents or actors) in games. Complex behaviors are created from hierarchies of simpler behaviors. Behavior groups like sequences and selectors explicitly structure how and when conditions for running sub-trees are checked and which actions to execute per simulation tick. Each behavior tree node visit executes the node and returns a result state. Inner nodes have different semantics how to handle child nodes and their return states.
Aaaand breath out. I told you it would be quick.
Naive sketch of an object-oriented behavior tree implementation
Looking at an example diagram of a behavior tree I can nearly smell the classes and their inheritance hierarchy.
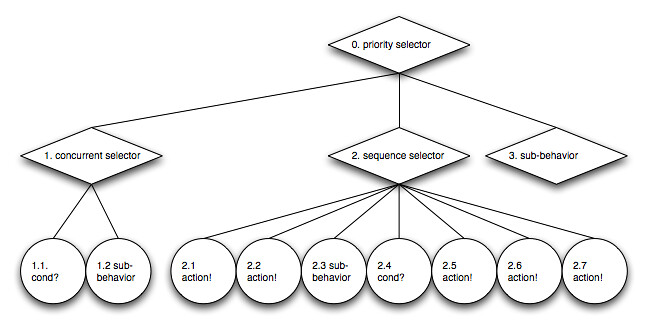{kind=link}
Let’s see – a behavior tree consists of different nodes, some are leaf nodes and directly run specific actions while other are inner nodes with type-specific semantics how to traverse their children. All nodes, regardless of their type, are traversed or updated during each simulation tick. Nodes return result states when they finish their update. As the intro article showed, we might also need to reset sub-behavior trees that returned a running state but aren’t visited by their parent node during the next traversal. Condition and actions node might need access to their actor’s world knowledge, so we should pass that in somewhere.
Here’s a first naive sketch for classes modeling a behavior tree – many details are missing but it contains enough specifics to explain the reason for my experiment:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | class BehaviorTreeNode { public: // ... virtual BehaviorState update() = 0; virtual void resetState() = 0; }; template class ActionBehaviorTreeNode : public BehaviorTreeNode { public: explicit ActionBehaviorTreeNode(ActionData* data); // Calls a certain member function of actor. virtual BehaviorState update(); // Does nothing. virtual void resetState(); private: ActionData* data; }; class SequenceBehaviorTreeNode : public BehaviorTreeNode { public: // ... // Iterate through children, start from next to run until done or a child returns that it is running. virtual BehaviorState update(); // Calls resetState for the next to run node as it might have returned a running state during the last update. // Prepares to start from the first child on next update. virtual void resetState(); private: std::vector children; // In sequence order. std::size_t nextChildToUpdateIndex; }; class PriorityBehaviorTreeNode : public BehaviorTreeNode { public: // ... // Iterate through children, start from next to run until the first one returns success or that it is running. // If this child's index is lower than that of the previous one returning running, rest the later child. virtual BehaviorState update(); // Calls resetState for the next to run child as it might have returned a running state during the last update. // Prepares to start from the first child on next update. virtual void resetState(); private: std::vector children; // In highest to lowest priority order. std::size_t nextChildToUpdateIndex; }; // ... and so on with other node types... |
Nothing extraordinary to see and quite quick to implement (as long as you don’t go wild on creating an abstract group class all inner nodes should inherit from to centralize child handling and node editing and perhaps add a factory, too, to separate creation of a behavior tree from its update processing, and…). If it runs on your target platform and doesn’t show up as too slow while profiling you are golden. Especially small teams with tight deadlines have so many features to work on that a solution that performs good enough actually is good enough.
Pitfalls of Object Oriented Programming. His presentation identifies the culprits of object oriented programming which neglects memory access patterns and the target platforms memory system needs and demonstrates how rewriting an object-oriented scene tree to a stricter data-centric representation results impressive performance gains.
Behavior trees have been invented and are used to enable easier modeling, tuning, and understanding of behaviors and their interaction with game worlds. Performance and how this model uses hardware was – if at all – only a second thought. However, the way gaming platform evolve (see the next section), bad memory access patterns can kill runtime performance, and there is a lot in the code sketch above that is nagging me:
- Traversal of such a behavior tree implementation means to follow pointers to nodes – all of these result in random memory accesses – bad for caches and when memory latency rears it’s ugly head.
- Calling
updateon an inner node recurses into its children, and so on. In effect, call stack depth isn’t controllable. This might be a non-problem for shallow trees though. - Additionally, each call of
updateincurs an indirection penalty for looking up the actual member function in the virtual function table (vtable) of the class. Lots of potential data and instruction cash trashing ahead! - On heterogeneous architectures or platforms with non-unified memory address spaces, e.g. the difference between main memory and local storage of the Cell SPUs, or the host and device memory of GPUs, trying to move such a pointer based graph involves a full serialization – copying of all nodes and fixing up all the pointers – no simple way to copy the whole behavior tree in one go, or to stream it easily.
- During traversal, leaf node actions are called. These actions might and will crunch through action-specific data. This will trash the cache. And if you run different behavior tree traversals in tasks on different worker threads there is no coordination of the memory accesses, no coordination how shared memory or caches (if existing) can be exploited.
- Worse: the user of the behavior tree system can implement her own classes with arbitrary data access patterns and pointers into other game systems. The behavior tree system can’t do anything to prevent possible race conditions if the user forgets to synchronize access to shared data but still runs the behavior tree of different actors in parallel. I won’t even start talking about the performance penalty because of effective serialization due to correctly synchronized accesses to shared data.
Template-based fast dispatch calls might replace the vtable lookup costs and a task queue system can help to get the call stack depth under control (both techniques are deployed by the excellent behavior tree implementation in the AiGameDev.com). Nonetheless, the underlying data access problems are reason enough to search for a different runtime representation of behavior trees – and that’s what this blog series is all about – a learning experiment.
It’s time to get to know the “enemy”, the environment to host your game – the hardware of gaming platforms that giveth and taketh performance according to it’s use.
Beware the hardware walls
Back in the day processors became faster and faster thanks to increasing clock frequencies, exploitation of instruction-level parallelism (ILP), and putting more and more local memory or caches into chips to minimize the necessity to constantly access the slower main memory. However, higher clock speeds lead to more heat, more complex features lead to more transistors which lead to more heat and diminishing performance in return, and – BAMM – headfirst into the following walls – nicely presented by Dr. Cliff Click and Brian Goetz in 2009:
- Power wall
- Physical limitation how much heat we are able to dissipate economically due to growth in power consumption because of clock frequency increases.
- Complexity wall
- Spending more and more transistors for branch prediction and speculative execution has diminishing performance returns. Complexity of the architecture and increasing transistor counts to implement advanced features need to be justified power- and performance-wise.
- Speed of light
- Physical limitation of the distance information can propagate on-die per clock tick.
- Memory wall
- While memory bandwidth and access speeds increased over time, they haven’t kept pace with processor speed development as David A. Patterson observed in 2004. Todays central processing units (CPUs) wait more cycles than ever for data to arrive from main memory.
Hardware vendors fight the first two walls by investing the still increasing transistor counts per die in more and more cores per processor. These cores are often simpler than their single-core CPU brethren. More cores equal more computing potential while each core’s speed doesn’t increase much anymore. Many cores with stagnating or even lower clock frequencies directly translate into lower power requirements and therefore less heat production.
Another wall-defeating-strategy is the introduction of heterogeneous processors – processors which combine cores of different architectures on one die or in one physical processor package – think graphics processing units (GPUs), vector processing units like SSE, or the Cell Broadband processor with PPUs and SPUs on one die. A core specialized for a certain task is more efficient (power- and performance-wise) than a general purpose processing unit working on the same class of tasks.
Even before going parallel, CPUs tried to overcome the memory wall by having a hierarchy of memory embedded into them – the nearer to a core, the faster, and the smaller the memory. Some architectures, for example x86 processors, automatically make use of their caches without the programmers involvement, while the local storage of the Cell’s SPUs and the different memory pools of some GPU processors belong to different memory address spaces and need to be explicitly controlled by programmers.
Complexity, power requirements, and scalability of core counts of the different memory hierarchy architectures aside – one point always stays true: cache misses and waiting on data to arrive from main memory severely limits performance of single and many-core processors. Acknowledging the latency elephant in the room – as Tony Albrecht called it – and optimizing data and data access patterns is the key to fully exploit a platforms performance potential.
Don’t fall for the Vincent Scheib).
Catchphrase inbound: data-oriented design
At GDC 2011, Culling the Battlefield – Data Oriented Design in Practice how replacing a tree structure to cull content from rendering and simulation with brute force array processing results in immediate performance gains, simpler code, and enables easy to apply further performance optimizations.
He applied – prepare for the climax of this episode – data-oriented thinking and design (DOD). Data-Oriented Design Now And In The Future.
To summarize, what does data-oriented design mean?
- Think! Think harder! Think about the problem to solve, the constraints to respect, the different possible solutions and their advantages and disadvantages:
- Focus on the expected output data first.
- Then, look at the data from which this output is computed, and
- finally consider the input data to gather.
- Treat code only as a means to transform data from one representation to the next.
- Concentrate on the data representation of the solution to minimize memory access costs, to maximize locality to your target platforms caches or local storage. Simple arrays can beat complex data representations thanks to their contiguous memory layout.
- Where there is one, there are many – think in batches of data items instead of items in isolation. Sort items based on their usage to circumvent conditional type-checking (via
if-then-elseor vtable-lookups) of each individual item. - Further on, identify and order data for access patterns – read, write, read-and-write – and organize computations in stages. Shared data that is read but not written in one stage can be processed in parallel without the danger of race conditions. Data items writes without any dependencies on other items can safely happen in parallel, too. Instead of performance-impeding synchronization per data item, only a few stages separating synchronization points are needed.
Interestingly, often data-oriented design doesn’t only result in faster computations but also in simpler and more modular code. Code that is easier to write, debug, maintain, and optimize – thanks to thinking of data and how fits the target platform first.
The end
The latency elephant (I love this term) is here to stay. Deal with it! Linear memory accesses allow access prediction and prefetching and beat random memory accesses – random pointer following. Organizing data based on its use and keeping its memory footprint small enables locality of data, minimizes cache trashing, and it saves memory bandwidth – especially when many cores otherwise threaten to saturate the memory system.
Bridge builders need to adhere to physical rules – software developers and especially game engine developers need to know their target platform(s).
After the introduction to behavior trees, and our first encounter with data-oriented design, everything is now prepared for the epic (ahem) third episode – the episode in which I’ll finally (this time for real, I swear) show you the design of my experimental behavior tree. So, haha, here comes the promised interrogation, what do you think:
- What is it that you want from a behavior tree – what output should it generate?
- How does the data look that represents a behavior tree. In which way is it used / traversed – are there obvious access rules?
- What data is changed during traversal and what data isn’t modified?
- What’s the input a behavior tree update needs?
And, if you are already using behavior trees in the current game you are working on:
- How many different behavior trees do you have in-game?
- How many nodes do they contain?
- Do they show up during profiling at all?
- Where and how do you run behavior tree updates – in parallel on multiple main cores, or even on SPUs?
To be continued
I’d love to hear back from you and hope that I didn’t generate too much hype for what I’ll share with you in two weeks. My cheap Hollywood-thrill writing be damned ;-)
Cheers and bye,
Bjoern
References
References from the article in order of appearance
- Tony Albrecht, 2009.
- AiGameDev.com .
- Not Your Father’s Von Neumann Machine: A Crash Course in Modern Hardware by Dr. Cliff Click and Brian Goetz, 2009.
- Latency Lags Bandwidth – Communications of the ACM by David A. Patterson, 2004.
- Tony Albrecht, 2009.
- Mike Acton, 2008.
- Vincent Scheib, 2008.
- Daniel Collin, 2011.
- Noel Llopis, 2009.
- Noel Llopis, 2011.
Behavior tree series
- Introduction to Behavior Trees
- Shocker: Naive Object-Oriented Behavior Tree Isn’t Data-Oriented (this text)
- Data-Oriented Streams Spring Behavior Trees
- Data-Oriented Behavior Tree Overview
- Behavior Tree Entrails