{kind=link}
How to get behavior trees with their branches, situation dependent traversal, and their non-regular data access patterns to play nicely with the memory hierarchies of game platforms? How to put data-oriented design into practice? What about quick iterations and tuning of behaviors at runtime?
These questions triggered my data-oriented behavior tree experiment. After getting to grasps with the concept of behavior trees in the first article, and understanding that a platform’s memory system is key to exploit it’s performance and how data-oriented thinking caters to it in the second article, the time has come to bring this knowledge to fruition.
Article Updates
- May 01, 2011 – Re-posted bjoernknafla.com.
Goals and requirements
Why behavior trees – what problem should they solve and which requirements need to be fulfilled for my experiment?
Behavior trees are a tool, a model, to describe actor behavior and the decision process leading to it by hierarchically compositing sub-behaviors. Behavior nodes have clear semantics how they influence tree traversal and therefore bring order and structure to the traversal-driven update of an actor’s decision process and the resulting behavior execution. The model should:
- Ease creation and comprehension of an actor’s decision making process.
- Simplify reuse of behaviors and creation of libraries of reusable behaviors.
- Enable fast iteration times for experimenting, tuning, and polishing of in-game behaviors.
- Allow straightforward debugging and, eventually, visualization of an actor’s inner workings.
It’s worth repeating: fast iteration times are an immense help to craft playful experiences.
A game might just sport a couple of entities (aka actors) controlled by behavior trees – or hundredths to thousands. In both cases game AI (artificial intelligence) typically only gets a small time budget per frame and the behavior trees shouldn’t take away cycles badly needed by navigation and line-of-sight based sensing. Available, precious cycles shouldn’t be wasted by waiting on data to arrive in a processor’s core registers. For my experiment, the following factors are important for efficient decision making and actor control at runtime:
- Minimize cache trashing, minimize random memory accesses – beware of the latency elephant.
- Enable movement of an actor’s behavior tree data to memory local to computational cores – be it as a whole or by streaming it in chunk by chunk.
- Be frugal with memory bandwidth – keep memory needs small and exploit data sharing inside the memory hierarchy.
- Know worst-case memory usage to allow preallocation and ease running on game consoles.
- Don’t loose control over call stack depth.
- Take advantage of parallelism.
To summarize – the modeling or development-time aspect calls for flexibility and quick changeability while the runtime aspect demands processing efficiency and high performance. These requirements oppose each other drastically – therefore my main experiment hypothesis is to use separate representations for development-time and runtime representation of behavior trees and connect them neatly to get the best of both worlds – though I might have to pay a penalty in implementation size and complexity.
Runtime behavior streams
Behavior trees are a decision and character control mechanism. Decisions are based on checking the actor’s highly individual situation and world knowledge. There’s is no way (I can see) to get around using conditions and branching – but we can minimize their impact and lessen their tendency to drag in unpredictable data to a performance hindering cache trashing party.
Ok, time to unwrap the big fat gun – data-oriented design. As It’s not just a way of getting some specific performance benefit. It’s how you understand problems deeply. To find a solution for a problem we need to know what we want out of it – what output data do we need to feed into other parts of our game? Which input data is required to get to the output, and how do we organize the data to simplify and propel transformation of input to output data?
What’s the output we want from behavior trees – what do we need from them?
Well, it’s in the name – we want behaviors. Hm. Still a bit abstract. Behaviors are interesting because of their observable outcome, the executed actions and the internal processes to enable these actions. Briefly, behavior tree decisions control an actor via actions to execute – where to move, what should be attacked, how and when. This directly influences navigation, animation, physics – the game state.
What input data is needed for this?
Decisions are based on the world knowledge of each actor. Crysis store this actor specific world view in blackboards. It changes from frame to frame, simulation tick to simulation tick.
The world knowledge and the last traversal state of an actor steer the next traversal of the actor’s behavior tree structure. Therefore representations of the tree and an actor’s traversal state are needed.
How is the input transformed or translated to the output data?
Updating an actor by traversing it’s behavior tree means to translate the tree based on the last traversal state and it’s current world view into actions and commands to run by other components of the game.
Enough with this high level inspection – let’s go deeper underground.
Output – harvesting behavior trees
A naive behavior tree implementation would execute leaf node actions during its traversal and, as actions like pathfinding, environment sensing, or animation generation can be very data intensive, would repeatedly trash caches on the way. Running these actions has side effects on the game state – but these side effects are hard to grasp as output. Also, as behavior trees are general modeling tools, it isn’t clear what kind of actions will be used by the behavior tree creator – and what kind of data will be accessed.
Deferred actions and action request streams
Therefore, actions shouldn’t be called on visiting a leaf node of the behavior tree but deferred to run later in associated systems that can organize their data for optimal (parallel) processing, e.g. via batching. Deferring means to collect action commands or action requests without needing to handle the data actions operate on immediately – one source of cache misses defeated.
These action request collections – typically streams aka arrays of commands – can be analyzed and sorted to batch them to their respective systems later on. If we know which resources, e.g. parts of an animation skeleton, are affected by actions, we can also benefit from the sorting by detecting possible clashes where different actions want to manipulate the same resource. Awareness is the first step to appropriately treat such collisions.
Deferring has downsides – selection of an action to run and action execution are separated in time and in code. This complicates debugging. And – it adds lag. During traversal of an action emitting node the final action result state isn’t immediately known. Instead of the final behavior result state, node traversal returns the running state – an action has been requested – it can be understood to already run without an end-result yet. The action might finish before the next tree traversal process or later. On finishing, the result state, e.g. success or fail, etc., needs to be made accessible to the action node, so the traversal process can react to it during the next traversal.
Persistent actions
By recording traversal and action call statistics, actions can be identified that are running nearly every time, e.g. for sensing. By separating these persistent actions and running them always before tree traversal we get rid of the lag and can still execute them in a data-optimized way, though the computed values might not be used during each update. During traversal the nodes representing persistent actions will often return success states – they already did their work and traversal can go on. However other return states are possible, for example to reflect that an action takes multiple time steps to finish or to signal that a special sensing action “failed” because it couldn’t detect nearby troublemaking entities.
Immediate actions
Certain actions might not even be represented as nodes in a behavior tree but run from time to time inside some game component system and aggregate world knowledge for the actor. Traversal of an actor’s behavior tree is dependent on the world knowledge to make the best decisions. Conditions check the actor’s blackboard for certain informations, e.g. evaluated sensor data, to affect traversal. If the amount of actor specific data to inspect fits into local cache or storage or can be streamed in as chunks then it makes no sense to defer these checks. Therefore immediate actions which only access actor private data are executed immediately during traversal to keep the behavior tree update going.
Traversal state
On closer inspection, each behavior tree traversal produces an actor specific traversal state that affects the next traversal, e.g. which sequence child node to re-visit next because it returned a running state. The actor traversal state is an output to feed back as input for the next update.
Input – fertilizing behavior trees
We already identified the following input an actor’s behavior tree update needs:
- Result states of persistent and deferred actions.
- Actor private data used by immediate actions and conditions – a blackboard.
- The last traversal state to pick up from.
- Let’s not forget the behavior tree structure or shape itself which can be understood as input data, too.
Action result state arrays with a slot per action node
Storing action result states can be handled by having a result state array per actor for the deferred and the persistent actions. The behavior tree shape dictates the exact action-to-state-index mapping (see below). Each action request result is actor specific and has it’s own state slot in the result array – deferred and persistent actions might be processed in parallel and their result can be easily written back without needing any synchronization to prevent race conditions (as long as the slots to write to are correctly memory aligned).
Having a fixed slot for each possible action result state can also be used to detect which actions haven’t been re-visited during the last update. An action might have returned a running state but another request to run it hasn’t been emitted. By comparing the return state array with the action request buffer we can emit cancellation requests – if the action-handling system needs these. All result states need to be reset to ready if their associated actions hasn’t been emitted during an update step, e.g. to prevent a stuck success state from a few simulation steps ago to always return success and therefore never emitting it’s action again.
Dynamically sized action result state queues
Action result states could also be stored in a queue. By sorting the states according to the order in which their associated action nodes are traversed we can speed up access to them. As not all actions will be requested during each update this method would need less memory to store result states.
Without a way for the behavior tree system to find out which previously requested actions haven’t been requested again, e.g. because traversal skipped the node emitting them, the action-handling components need to detect such missing re-activation and cancel actions on their own or just execute actions on request without storing any persistent action request data between updates.
Actor private blackboard
If we only target CPUs optimized for low-latency and conditional computations, like most x86 compatible processors, we can represent the actor private data via a void pointer or an any type and cast it explicitly before accessing it. To run behavior tree updates on the SPUs of a Cell processor, or even on a graphics card via OpenCL or CUDA, we need to know more about the blackboard data to move it from main memory to local storage or from host memory to device memory. It could be represented as a byte buffer of a specific size or as a simple dictionary type description as presented by Niklas Frykholm in his #AltDevBlogADay post Managing Decoupling Part 3 – C++ Duck Typing.
While the behavior tree structure and an actor’s traversal state are input data for each update, their representation is heavily influenced by the traversal process. Therefore they are described in the next section.
The joy of climbing – traversal of behavior trees to translate input to output data
Ok, here we are – do you feel it? There is something special about this moment – welcome to the inner sanctum of this post – the runtime behavior tree representation itself and it’s associated actor traversal state. How to approach its design? Should we fall back to the naive object-oriented behavior tree sketch from my last article?
A resounding hell no!
To find out how to represent something we need to understand it – how is it used in detail? Sample it if you have access to real data!
Timber! Flattened by traversal
Let’s look at the example behavior tree of my first post in this series again:
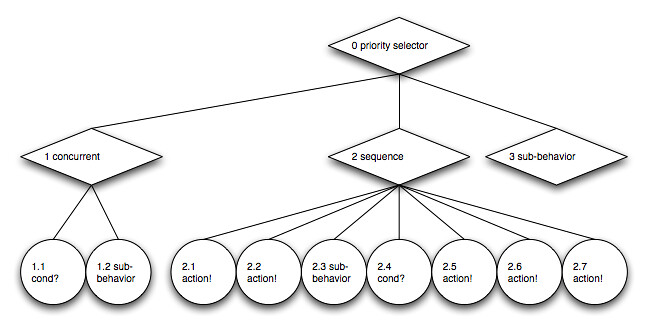{kind=link}
The root node is now a priority selector that re-runs a child node that returns running instead of selecting a new child to run on each traversal. Node 3 is a placeholder for a whole sub-behavior tree.
Let’s trace a first traversal path through it:
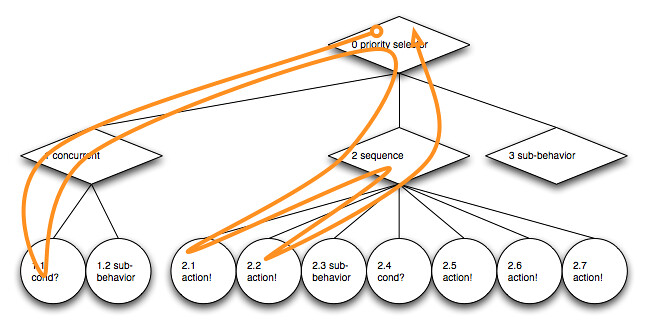{kind=link}
During the update the priority selector 0 first tries to execute it’s first child – concurrent node 1. However, it’s first child 1.1, an immediate action checking for a certain condition of the actor’s blackboard data, fails. Traversal returns to the root priority selector which tries it’s next child sub-tree. This sequence, node 2, visits it’s first child 2.1. This immediate action returns with success so the sequence runs child 2.2, which emits a deferred action request and returns running. The sequence bails out with a running result state, too, as does the priority selector. The first traversal is finished. The traversal path is symbolized by the orange line through the symbolized behavior tree.
Traversing through a behavior tree leaves a linear path as it’s trace. A behavior tree update starts as a depth-first traversal from its root and is then steered by the traversal semantics of the inner nodes. Each inner node is visited by entering it. Based on an inner node’s update semantics, one of it’s children might be visited. On returning from a child sub-tree the inner node is visited again to react to the returned child result state and decide if to enter another child or to leave the inner node. The zig-zag line between node 2 and it’s children visualizes this inner node to child and back traversal path.
Consider traversing the complete tree depth-first by visiting each node regardless of inner node traversal semantics:
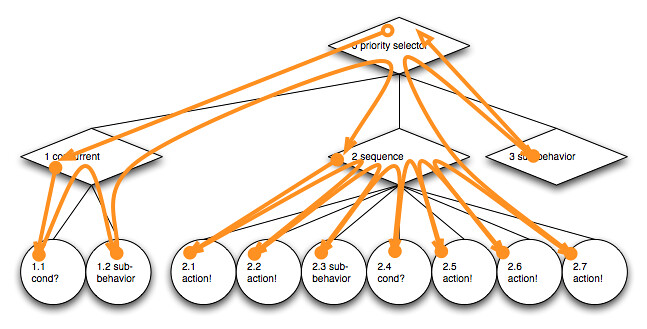{kind=link}
On each first visit of a node we assign a number to it. The assigned value is incremented from node to node. When starting at the root node with 0 we enumerate all nodes:
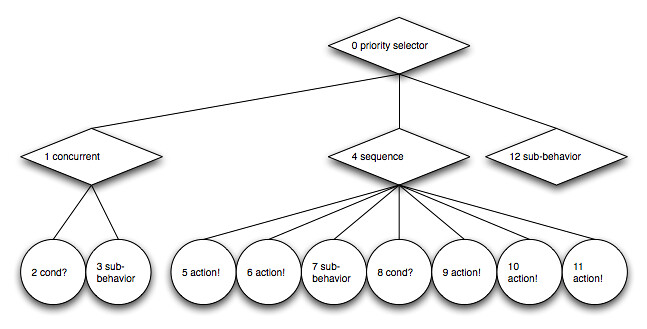{kind=link}
To simplify further traversal diagrams the node type names are removed and node symbols are shrinked:
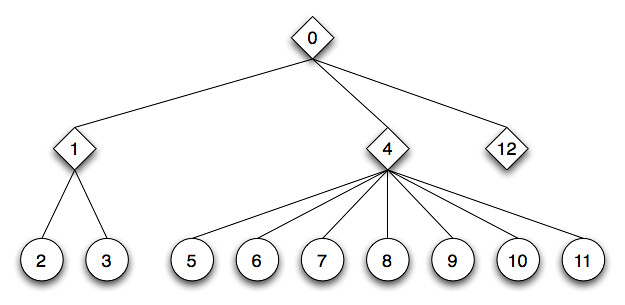{kind=link}
Now, interpret each node’s number with an index into an array – or stream. The whole behavior tree is flattened into a contiguous array of tokens – plain old data-structures (PODs) representing nodes. Inner parent node tokens always precede the flattened sub-trees of their child nodes. This behavior stream describes the – albeit flattened – structure of the behavior tree – it’s shape – it’s also called a behavior tree shape token stream (woohoo for growing terms longer and longer, ahem):
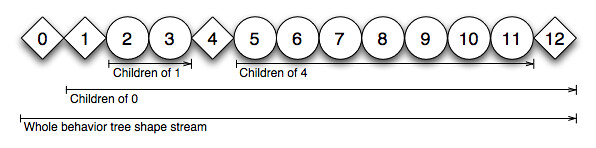{kind=link}
All actors controlled by the same behavior tree share it’s shape. However, an actor’s traversal state based on the actor’s world knowledge is specific to the actor – and therefore not shared.
A typical tree traversal iterates over the stream by starting from the root token at index 0. Inner node representing token affect iteration, e.g. by skipping a range of indices occupied by flattened children sub-trees to jump right to the last selected child to run. Jumping to a child means to iterate to the index of the root node token of the flattened child sub-tree.
When a behavior sub-tree returns it’s parent needs to get the chance to react to the result state to decide if to proceed to the next child sub-tree (the zig-zagging) or to leave and hand traversal decison-making over to the higher-up parent node. How to keep track of the parent node and it’s traversal semantics to react to the returned state? One solution is the pure stream or shape stream only approach, the other way I can think of comprises the use of a traversal stack. Both methods allow to iterate from shape token to shape token and keep the function call stack flat – for handling a token an associated function is called based on the token type. After the function is left it’s the turn for the next token in the stream. Naive tree traversal would call an update function per node which itself calls the update functions of it’s children – the result: loss of control over function call stack depth.
Pure stream traversal – no shaking, nor stirring
The most straight forward zig-zag handling is to not only store a single node-representing token in the behavior stream but to store an additional token behind each flattened child sub-tree of an inner node. These special guard token store information how to react to result states of the child sub-tree they “guard”. A sequence guard token would react to a fail return state by jumping to the token behind the last of it’s child guards – the end of the token range representing the sequence sub-tree and all it’s contained direct and indirect children. The jump will land on the guard token of the sequence’s parent node. Let’s call this idea the pure stream traversal approach to handle the semantics and scope of inner nodes.
Here is the flattened example tree including guard token (marked with a “g” behind their associated inner node depth-first assigned number), the orange line shows the traversal direction and traversal trace:
{kind=link}
Back to the above behavior tree update example – this time we annotate each node visit of traversal 0 with a character A to K:
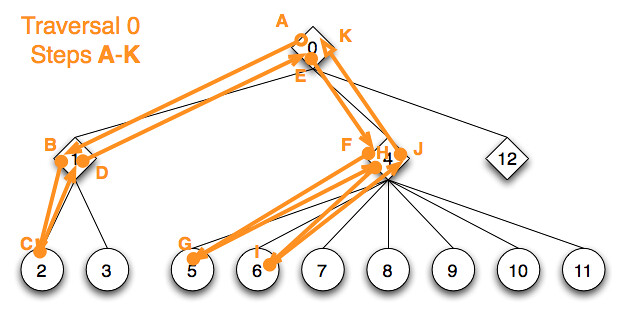{kind=link}
And here is the associated pure stream traversal:
{kind=link}
Instead of marking guard tokens explicitly they just show up with the symbol and number of their inner tree node. The pure behavior shape token stream is iterated in one direction and unvisited node tokens are simply skipped along the same iteration direction.
The next behavior tree update picks up traversal from the last running child of the root node. The child, sequence 4, traversal state directs traversal to it’s last running child, node 6, whose emitted action already finished with a success state which it set for the actor. Therefore traversal goes on to the shape token of node 7 which emits a deferred action request and immediately returns running as a result. With the running behavior state the token for node 4 and 0 both bail out.
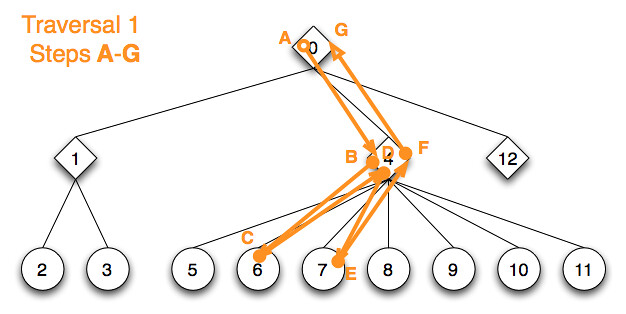{kind=link}
For the pure stream representation this traversal looks as follows:
{kind=link}
The whole flattened hierarchy of node 1 and it’s children and child guard tokens is skipped. Sequence node token 4 directly jumps forward to it’s last running child, the token for node 6, to continue the update traversal. It returns with success and the guard token for the inner node token 4 decides to move on in the sequence – to token 7. After token 7 requested it’s associated deferred action, the guard token behind it decides to leave the sequence with the running behavior result state and skips forward to the next sequence guarding token of node 0. This guard token bails out with the running state, too. Traversal 1 is completed.
Traversing accompanied by a traversal stack
Another way to handle the zig-zagging is to use a behavior stream of shape token which only contains one token per tree node, and use a traversal stack during updates to push and pop inner node scope representing stack token to/from it. A behavior tree can be analyzed to determine the maximum traversal depth and therefore stack size necessary.
While iterating over the shape token stream a stack token is pushed onto the traversal stack whenever an inner node token is encountered/entered. On finishing processing of a shape token the top traversal stack token is examined. It defines the parent node the last shape token belongs to and decides how to handle the returned behavior state of the last processed shape token. It also contains information about the index range of the direct and indirect children of it’s inner node. Therefore it can decide if the last processed token index still belonged to the inner node index range or not.
To bail out of an inner node the traversal stack is popped, the stream iteration index is increased to leave the index range of the inner node and it’s children, and (if it exists) the new top stack token handles the bailout result state. It might just select the first shape token of it’s next child sub-tree to traverse into or it might bail out, too, with all the popping and iterator increase described above, and so on.
Let’s look at the following depth-first flattened behavior tree example again:
The traversal stack token of priority selector node 0 knows that it’s sub-tree spans the token index range from 0 (the inner node of the stack token itself) to 12. The traversal stack token of the inner node 1 spans the index range from 1 to 3, and the index range or the stack token for sequence node 4 goes from index 4 to index 11. For example, if node 5 returns a success result behavior state, then the stack token for it’s direct parent node 4 sees that it’s still inside it’s range and that stream iteration should proceed to token 6. However, if the token for node 11 returns with success the stack node token detects that it’s the last child of sequence node 4 that returned, so the sequence is left and the stack token of the parent node of the sequence should decide how traversal goes on.
Think of a stack token as a single guard reused for all children of an inner node.
This is the traversal stack methodology. An exemplary behavior tree traversal with it is shown in combination with traversal state handling below.
Pure stream versus traversal stack guided traversal – fight!
As each node other than the root node is a child, and each child node token is accompanied by a guard token, the numbers of shape tokens to store is doubled for the pure stream approach. Though, no memory is needed for a stack during the traversal of an actor. As the stack only needs to hold as many token as the behavior tree is deep, the traversal stack technique needs less memory than the pure stream.
Platforms with huge memory bandwidth but small per-core local cache or storage favor the first approach, while platforms with bigger per-core local caches/storage and perhaps less memory bandwidth are a better fit for the traversal stack idea as they can keep the traversal stack in core-local storage and tax the memory system less because the behavior stream shape needs less memory and might be shared by multiple worker thread running cores which share a cache.
State of the nation – aeh, traversal
During the traversal description I sneakily dodged the traversal state topic – time to confront it to complete the picture.
An actor’s traversal state needs to be preserved so the next update traversal can pick up from the last running behaviors and also to keep note of counters or timers hosted by decorator nodes.
Behavior trees without concurrent nodes have at most one concurrently running action. In a pure stream representation we’d need to only store the node token index where to restart traversal from. The guard token behind the last running token directs traversal steps along the behavior tree hierarchy of nodes afterwards. In the traversal stack approach, the traversal scope – the traversal location in the behavior tree – is encoded in the traversal stack. Keep this stack for the next traversal and restart it from the last running child of the top traversal stack token.
Concurrent node semantics complicate state storing
When concurrent node semantics enter the picture, multiple running behaviors can co-exist after an actor’s behavior tree update and need to be taken into account when starting the next update traversal. A single shape token index isn’t enough anymore to begin the next traversal. As concurrent nodes update all their children during traversal, the highest up concurrent node needs to be known to pick up the next traversal from it. And to traverse into the correct nodes below it, e.g. the child that was last running in a sequence, child node states need to be accessible and therefore collected. State collecting and handling resembles the one of the traversal stack method – which is explained more closely below.
A state slot for each node
Concurrent nodes with multiple active children transform the traversal stack into a stack cactus (a tree) to mirror the traversal state of all branches containing running actions. Dynamically storing a tree of states doesn’t seem very memory access friendly. As we already flatten the behavior tree shape into a stream we can also flatten the state tree into a state stream where each state entry is associated with a shape stream token.
Buffering state only when necessary and for the last visited nodes
Stack-based traversal always starts at the behavior tree root and uses the state stream to steer traversal to the behaviors that were running during the last update step. In the simplest case each node that needs to remember it’s state can have it’s own data-slot in the state stream. A more complex and less memory requiring solution is to only store the state for shape token when it is different from the default initial state of the associated node, e.g. only store the next child to visit for a sequence if the sequence doesn’t start traversal from it’s first child. This also implies to only store state for nodes visited during the last traversal instead of supplying every node with a state slot.
Collecting states during traversal on leaving inner nodes
In both described cases a buffer is used to store the last behavior tree traversal state. For most inner nodes we only get to know their traversal state after they are left – after the last child they ran successfully or which returned running is determined. However on leaving the scope of an inner node many direct and indirect children of it might have been traversed already – many of which stored their own traversal state. The traversal state of their parent would therefore be located behind all of it’s children states. The solution using one fixed state slot per shape token enables a jump back to the shape token slot – but that would lead to a lot of random memory accesses during a tree traversal – that’s not an option I want to investigate.
Collecting states in fixed slots per shape token
To keep the forward momentum of traversal over the shape stream and the traversal state array just add a state slot for an inner node behind the state slots for all of it’s direct and indirect children. During a cleanup phase after an actor update the states can be moved to the beginning of their inner node state ranges.
Collecting states in a dynamic state buffer
Without a state slot per node but a state collecting buffer all traversal states are collected and stored together with the index of their token in the shape stream. After an actor’s behavior tree update traversal this buffer is reordered – be it by sorting it according to the shape token indices stored in it, or by iterating over it backwards and using a special traversal stack to reverse the order of inner node traversal states. I’ll describe this last approach in more detail in a later blog post. This reordering results in a traversal state stream that can be completely traversed in forward direction.
During the next traversal, the shape stream and the traversal state stream are iterated together. When the currently accessed shape token index corresponds to the shape index stored in the current state token, it is read and both stream token indices are incremented. Should the shape token index stored in the current state token be greater than the currently traversed shape stream index we have entered a sub-behavior that wasn’t active before – and as there is no associated state to be found we just use the shape’s default initial state. The moment the shape index of the currently selected last traversal state token matches the index of the shape stream iterator we use the recorded states again. Should the current traversal skip parts of the behavior tree which have entries in the state stream we detect that the current shape index is greater then that of the current state stream token. Then we just run along the state stream until we hit the first state’s shape index that is equal or greater.
Decorator node traversal states
Oh, not to forget – we always need to store decorator states, like timers or counters, if they are different from their default start settings. These states can be folded into the main state stream or get their own buffer – which I prefer currently. I assume that their number is quite small and to fit a L2 cache or local storage of an SPU easily – so jumping forward and backward in this special state buffer shouldn’t be problematic. As timers need to be maintained even if their decorator node isn’t updated all the time during the timer lifetime, I call these traversal states persistent.
Example behavior stream traversal with a traversal stack and a buffer to collect node traversal states
But enough of abstract descriptions – let’s put all eggs into one basket and use the already introduced behavior tree traversal example to study how a traversal stack and the traversal state of an actor guide iteration over the behavior tree shape token stream. A quick reminder how traversal step 0 looks like:
Here is the associated shape stream shared by all actor’s controlled by the behavior tree, and the traversal stack, the last traversal state stream and the buffer to collect the next traversal state for updating an actor:
{kind=link}
The last state stream is empty – all nodes are in their default initial traversal state, e.g. a sequence will start with it’s first child sub-tree.
The shape token symbols are faded out as they haven’t been traversed during update 0 yet:
{kind=link}
The first iteration step enters the token for the priority selector root node 0. Without an associated traversal state it visits it’s first child 1. The priority selector is an inner node and therefore pushes a priority selector traversal stack token for it onto the traversal stack:
{kind=link}
In step B the shape token of node 1 is processed. The concurrent node needs to react to the behavior result states of it’s children. To do so it pushes it’s own traversal stack token onto the stack:
{kind=link}
Concurrent nodes run through their children from left to right and only bail out early when a child returns a fail or error result state. The immediate action shape token for child node 2 is updated and returns fail:
{kind=link}
During step D the concurrent node 1 reacts to the child fail via it’s child guarding traversal stack token. It decides to bail out with a fail behavior state, too. This means that the traversal stack is popped (see figure for step E) and the shape stream iterator is advanced to leave the index range of the flattened concurrent sub-tree. As concurrent nodes always try to re-run all their children, no traversal state needs to be stored:
{kind=link}
After popping the traversal stack we inspect the (re-)appearing top stack token immediately to enforce the traversal semantics of it’s associated inner node – what’s the behavior return state of the last child and has the stream iterator reached the end of the stack token stream range? In the case of traversal step E, traversal is still inside the index range of node 0 and advanced to the second child sub-tree start token 4. As the first child failed the priority selector node tries to run this child:
{kind=link}
Processing of the token of sequence node 4 pushed it’s stack token onto the traversal stack and advances the stream iterator to it’s first child 5:
{kind=link}
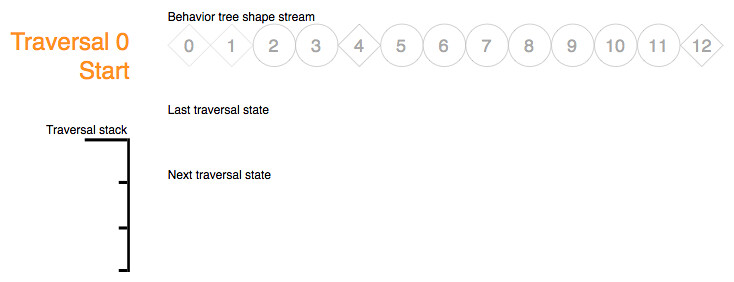
Processing of the immediate action token 5 succeeds during step G and the shape stream iterator is advanced to the next child of node 4:
{kind=link}
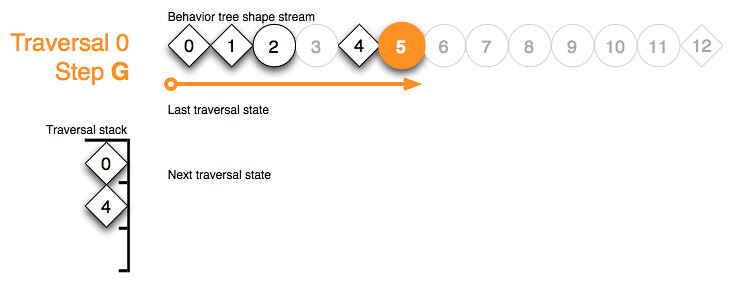
As always – after processing a shape token the top traversal stack token is interpreted to react correctly to the last returned behavior state. In the case of sequence token 4 it’s ok to traverse to the next child 6:
{kind=link}
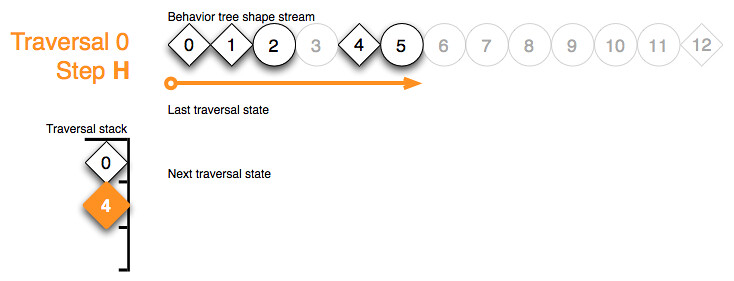
The shape token of node 6 emitted a deferred action request in step I and returned with result state running:
{kind=link}
Step J includes processing of the top stack token belonging to the sequence node 4. As a sequence is left when a child returns running it increase the shape stream iterator forward to the end of the range of the children (and their sub-children) of node 4. To prepare the sequence for the next update it’s traversal state – the last running child – is added to the next traversal state buffer. Leaving a sequence also results in popping it’s traversal stack token:
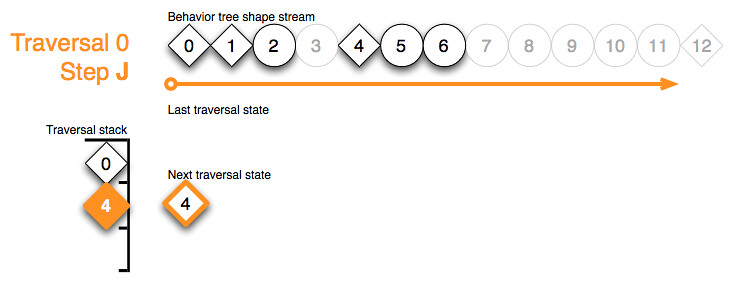{kind=link}
After popping the traversal stack the new top traversal token is processed. The stack token for priority selector 0 finds that it last tried child returned a running behavior state so it bails out running, too. To do so it first notes it’s last running child on the next traversal state buffer, pops the traversal stack, and advances the shape stream iteration to the end of it’s range:
{kind=link}
In step K the end of the shape stream has been reached – update traversal 0 ends:
{kind=link}
To prepare for the next update tick the next traversal state buffer is reordered:
{kind=link}
Next round – here is the path of next update – traversal 1:
Before starting update traversal 1, the reordered next traversal state is copied to become the last traversal state stream and the next traversal state is cleaned:
{kind=link}
Step A of traversal 1 processes shape token 0 – which detects it’s last traversal state on the last traversal state stream. The inner node traversal stack token is pushed onto the traversal stack, the shape stream iterator is forwarded to the last running child 4, and the last traversal state stream iterator is incremented:
{kind=link}
Shape token 4 finds it’s last traversal state during step B, increments the last traversal state stream iterator, skips the shape stream iterator forward to it’s last running child 6, and pushes a stack token onto the traversal stack:
{kind=link}
Since the last behavior tree update, the action requested by the actor via shape token 6 executed and succeeded:
{kind=link}
The stack token of sequence node 4 permits to advance to it’s child 7:
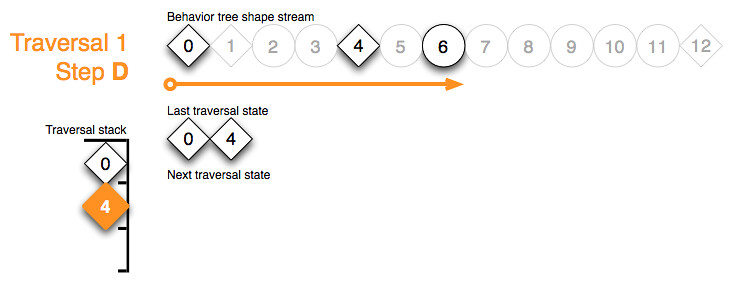{kind=link}
Shape token 7 requests a deferred action for the actor and returns with a running behavior state:
{kind=link}
The top traversal stack token is checked after each processed shape token. It decides to leave it’s sequence shape stream index range, adds the sequence traversal state to the next traversal state buffer, and returns running. The traversal stack is popped (see step G for the effect):
{kind=link}
As always: popping the traversal stack is followed by checking the new top stack token. Priority selector 0 observes that it’s child bailed out running. Therefore it’s job is also done – it’s stores which child to pick up from during the next traversal on the next traversal state buffer, skips forward to the end of it’s range on the shape stream, and pops the traversal stack:
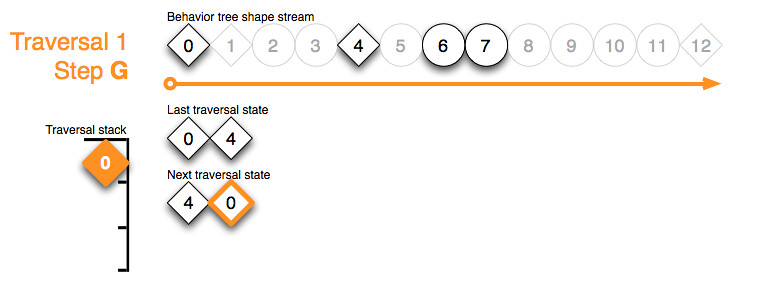{kind=link}
The end of traversal 1 has come – the end of the shape stream has been reached and the traversal stack is empty:
{kind=link}
We conclude the traversal example by reordering the next traversal buffer into stream order:
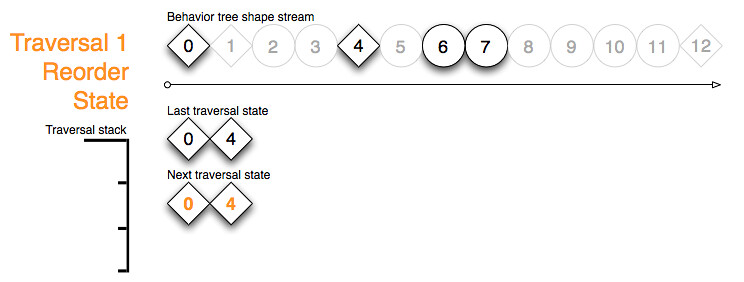{kind=link}
Please keep in mind that the token for a behavior tree node in the shape stream, the traversal stack, and the state buffers are all of different data types. And while I am at it – the traversal state identifies the next child to run for a sequence or selector node, or contains a counter or timer for a decorator node, while the behavior result state returned by a node specifies if the associated behavior succeeded, or is running, or failed or if an error occurred.
All together now – behavior stream processing
Phew, that was quite a loooong ride. Let’s summarize what we got:
- The structure aka shape of a behavior tree is represented by a behavior stream of shape token. This representation is shared by all actors controlled by the specific behavior tree.
- Each behavior tree contains a set of persistent actions to run for each update step of it’s actors.
- A set of result states for the persistent and deferred behavior tree actions is stored for each actor.
- After traversing an actor’s behavior tree, a collection of action requests to run by other systems or components of the game is generated. Each request contains enough informations to identify the actor and to write back the associated result state on action completion.
- The last actor update traversal state is stored in a state stream. A second state buffer might be used for long-lasting states of decorator nodes.
- A private blackboard contains actor-specific aggregated world knowledge. Blackboard entries might be produced by persistent actions. The entries are read and possibly written by immediate behavior tree actions.
Behavior stream shape token and the state buffers and state streams are ordered to enable a straight forward one-directional stream iteration. Each traversal generates a new traversal state stream and deferred action request buffer. To put it bluntly: behavior trees and an actor’s traversal state and action requests are completely represented in data and the data is stored in arrays. No pointers, just indices are necessary to traverse a behavior stream. The actor specific behavior tree update traversal translates this data and generates the next traversal data. It’s a bit like a virtual machine (VM) crunching through instruction and data streams, or like data flowing though a compute kernel.
Updating the behavior trees of all actors is divided into multiple phases or stages as seen in the figure below:
{kind=link}
Orange stages are under the direct control of the behavior tree component/system while white blocks represent stages interacting with the behavior tree stages but which are under the control of other components/systems.
During each game AI simulation step:
- All actor specific persistent actions are executed.
- Persistent and deferred action result states (
success,running,fail, etc.) are returned and set for the associated actors. Per-actor world knowledge blackboards are updated to ease implementation of conditions via immediate actions that can only access their actor’s blackboard. - Then all actor decision processes are run – their behavior trees are traversed.
- Each actor traverses it’s behavior shape token stream and it’s last traversal state stream and generates deferred action requests and the next traversal state.
- Afterwards the next traversal state collection is ordered to become the last traversal state stream during the next update.
- A per actor cleanup phase might detect if formerly running actions need to be cancelled, if non-updated states need to be reset to be
readyfor a later traversal, and timers of active but unvisited decorator nodes are updated, too.
- Afterwards all action requests of all actors are merged and prepared to be fed to their specific components.
- At the end of the game AI simulation step components execute the action requests they received in a data-optimized way.
The behavior tree shape isn’t modified during traversal and each actor works on its last and next traversal state and action request buffer in isolation. Therefore actor’s sharing a behavior tree shape should be batch processed together to exploit the platforms local storage or shared cache for the read-only shape stream. Each actor can be processed independently from other actors. By viewing actor processing as a task, these update tasks can run in parallel. We only need synchronization to merge the action requests of all actors which enables us to sort, chunk, and batch process the requests in their associated components or systems.
Action request result states target different actors or different result state slots per actor and can therefore be written sequentially or in parallel without safeguards.
Last but not least – repeating myself to ensure that I drive the point home – the shape and state tokens are plain-old data structures (PODs). A type id signals how to process them, how each influences traversal. A stream of tokens is just an array which can be easily moved, chunked, batched, or streamed into a cache or the local storage of SPUs or even OpenCL or CUDA device memory. The type id still leads to branching to call the right function to process each token – but without a vtable the data can be packed tightly in memory without further pointer indirections and their random memory accesses to handle polymorphism. With a pre-known and limited number of node types there is no reason to pay for the flexibility of inheritance.
Shape token for internal nodes only access an actor’s behavior tree data. Persistent and deferred actions run in their own, non-behavior tree related components. Immediate actions should only work on an actor’s world knowledge blackboard. As a result this should guide implementation of actions for clear data usage and minimize the chance to trash the cache while updating an actor because of unforeseen and uncontrolled data accesses.
The stream design looks like it should get rid of many random memory accesses. Even with the forward skipping over untraversed sub-tree stream reanges it might allow prefetching. However, only a testable implementation will show if it outperforms a more naive approach. The less “fat” the platform’s CPU architecture, e.g. missing out-of-order execution of instructions or branch prediction, the more visible I expect the performance gain to be.
Edit-time planted tree generates streams
Behavior trees – models of decision making – are crafted during development- or edit-time. Of equal importance to the creation itself is the a ability to look at them to comprehend how actor’s behave. The behavior stream concept caters for efficient and straightforward behavior tree traversal at a games runtime. Questions like how to create it, how to add and remove sub-trees to nodes, or how to edit it in code, via a scripting-bridge, or visually via a GUI (graphical user interface) have been ignored by me (until now). However, these are important questions – game AI is a craft, an art, that requires a lot of trial-and-error. Tuning of behaviors and rapid iteration cycles to immediately see the effect of changes unfolding in the game is essential to construct playful experiences for gamers. Being able to monitor the decision making process of an AI controlled character tremendously helps to understand it’s reasoning – and possible faults in it. A speedy runtime isn’t worth much without great control – traction – at development-time.
Editing only creates the structure of a behavior tree – a blueprint or scheme for the runtime streams – while the actor’s to be controlled by it only enter the picture during debugging or behavior monitoring. It would also be nice if changes of a behavior tree scheme are immediately adapted by the runtime behavior stream and the traversal and action result states of affected actors in a running game.
Development-time fruit picking – output
What do we want from a behavior tree at development-time?
During editing it should generate the runtime behavior stream and informations about the minimal size of actor traversal state and action request buffers. To adapt in-game streams and actor traversal and token states to the behavior scheme changes, a stream of change- or delta-commands is necessary. Different delta-command queues for the runtime behavior shape and the traversal states of actors might be sensible.
One kind of output is the visualization of the behavior tree scheme. In a model-view-controller (MVC) GUI architecture all model changes need to be transmitted to the controller and it’s connected views. It should be possible to connect the scheme view to an actor in a running game and visualize it’s behavior – the way it’s tree is traversed, too. In a sense, the messages send to the model observers are (albeit different) delta-commands, so we might be able to use the same mechanism to gather change-commands for the runtime and the GUI. The visualization is mostly interested in the hierarchical relationship of parent nodes to their child nodes and not so much in tree traversal oriented stream organization.
Another required output is a serialization format to save a behavior tree representation in a file or data base. It occurs to me that the memory streamlined runtime behavior stream might be a great storage format, especially as it would be easy to load from the game itself, too.
Feed the tree to grow, shrink, change – input
Storing a behavior tree involves the data to write – and this is also the data to read back. A behavior tree scheme should be create-able from a behavior runtime stream.
During edit-time, modification commands will be received from the GUI or via a script binding. Nodes are created, added to parent nodes, removed from their parent node, and finally destroyed. A mouse click in the GUI might request more information about a node – for example an attached name or text description.
To be able to create persistent, deferred, and immediate actions at edit-time, the actions that can be called need to be known – be it via a list of available action descriptions queried from the game or a game configuration file.
While monitoring actor’s in a game, information about the actions they request, their current traversal state, and eventually even their traversal path might be received.
Gardening time – process that edit-time data
I need to confess that so far I have put nearly all my time into the behavior tree runtime stream and only a few moments of thought into the edit-time scheme. Most of this section is more a collection of ideas and points to take into account than a coherent analyzation.
During development of behavior trees everything revolves around creation and editing of the behavior hierarchy – creation and destruction of nodes of different types and given parameters, e.g. the deferred action to request, and inserting and erasing these nodes into/from a parent node. These operations can happen inside C/C++ code, might be called from a script, or are kicked off via a GUI. The relationship of nodes to each other is the central data – no traversal takes place other than in the head of the developer who creates a new or tries to understand a given behavior tree scheme.
Informations the runtime requires from the scheme are:
- Size of the shape token stream.
- Configuration of each stream token.
- Size needed for the action request buffer per actor during an update.
- Size of the traversal stack for an actor update.
- Which persistent actions are involved – how many result states can each actor expect to receive pre-update.
- How many deferred action result states are at max received pre-update.
- Number of necessary persistent traversal states storage slots, e.g. decorator timers.
With behavior streams as the file or serialization format we can produce a scheme by iterating over all tokens in the shape stream – no skipping – and use guard token or a traversal stack to recreate the behavior hierarchy. Storing a scheme happens by the opposite depth-first traversal through the scheme hierarchy.
Changes in a behavior tree scheme should be reflected in the stream and the actor states of the connected game runtime. The edit-time component needs to know about the last behavior stream configuration established – the last runtime-ified snapshot of the scheme – and based on that collects delta- or change-commands to modify the shape stream, per-actor changes to the persistent and deferred action result state buffers, the persistent and last traversal state, and also needs to update the affected per-actor-update traversal stack size. Before committing these command queues to the runtime they are sorted according to the order in which they are applied:
- Adapt the buffer and stream sizes per behavior stream, actor, and the ones used by the update tasks. Eventually set up bigger sized modification buffers if the stream of change commands might grow the modification space needed larger than the final capacity.
- Remove shape token and the associated state slots per actor.
- Change indices to the new ranges after the change.
- Move tokens to their new places in streams and buffers.
- Add new shape token and eventually even new states created to steer the runtime behavior tree traversal during debugging.
It makes sense to analyze the delta-command queue to merge changes to optimize and shorten the number of changes, e.g. why add nodes via the first delta-commands if they are removed by later commands.
Integration of delta-commands happens during an additional edit stage in the runtime:
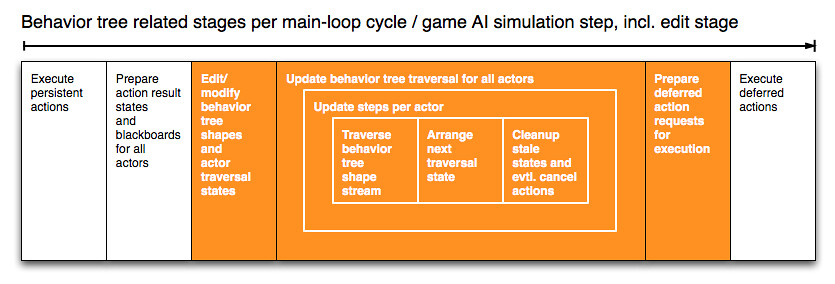{kind=link}
In a later blog post about modularity, behavior lookup nodes, and how to adapt behavior streams to runtime changes of characters, the edit-stage will play an important role, too.
For debugging and monitoring of runtime behaviors, the development-time component receives data from specified actors and behavior shape streams. The development side needs to be able to discover the game runtime, it’s behavior streams, and the associated actor states to allow selection of which actor(s) to monitor. Runtime extensions will be necessary to gather complete traversal paths. A mapping from shape token indices to edit-component nodes is necessary for visualization – I envision the highlighting of updated nodes in a tree to look like some kind of sparkling “christmas tree”. Additionally, a way to step an actor’s or all actors traversal in combination with runtime stream breakpoints might help debugging, too.
During behavior tree development the speed or efficiency of tree traversal doesn’t seem to matter. In a GUI, one behavior tree scheme is manipulated at a time instead of traversing through multiple trees and many actors per behavior tree. Perhaps debugging and monitoring of the runtime will require efficient visualization in the edit component – but before I know that for sure I’ll go for a pointer-based implementation of different node types as it mirrors the development-time focus on parent-child relationships in the behavior hierarchy most closely.
The delta-command order and the commands itself will define the runtime edit-stage component.
Inspired by Chris Edwards from Insomniac Games Nick Porcino for the suggestion) I plan to create a browser based GUI which connects to the behavior tree runtime in a game or to a game database. Be warned: this will take quite some time as I can’t put much (time) resources into the whole behavior tree project.
The end – hugging behavior trees and questions
At runtime, my experiment’s behavior trees are planned to consist of a shape stream shared by actor’s which use their own traversal and behavior result buffers aside a world knowledge blackboard. An update-kernel takes these streams and buffers to update one actor at a time – running multiple kernels or behavior tree interpreters on different actors in parallel enables parallel decision making.
Linear and predictable memory access patterns are favored over random memory accesses and might open the door for prefetching to hide memory latency. Data is organized tightly to fit into local storage or caches and to save memory bandwidth. Indexing array elements eases movement of data from one memory address space to anther, e.g. from Cell’s PPU to SPUs or from host to device memory in OpenCL or CUDA. The number of different behavior tree node types is fixed and small – performance and in-memory size of data isn’t wasted for unnecessary extensibility and indirection due to inheritance, polymorphism, and vtables. The behavior tree runtime system guides it’s user to do the right “things” in regard to memory usage – it (hopefully…) nudges her towards thinking in contiguous chunks of data instead of stumbling into a nest of pointers.
Deferring of actions and limiting immediate actions to only access an actor’s blackboard can be applied to object-oriented behavior tree designs, too, and might be guiding steps when refactoring them, should profiling pinpoint cache-miss problems.
Editing is all about model creation and tuning with fast iterations times. Streams of change-commands connect the editing component to the game behavior tree runtime to enable on-the-fly changes and monitoring of the actors decision making process.
The result: data-oriented runtime behavior streams spring development-time behavior trees.
According to the mouth-watering calltree project even go a step further than “just” interpreting a behavior stream at runtime and instead compile a graphical or language based behavior tree description into a more efficient runtime format.
Questions
Some points I wonder strongly about – mainly because I don’t have a true use case aka game for my behavior tree design yet:
- How precious is memory these days – would the pure stream approach with guard token doubling the behavior stream size use too much memory for todays consoles?
- Related to the last question: how many nodes do your behavior trees sport, how many behavior trees are used per level – and how many actors share the same tree?
- Should I foresee a way to explicitly cancel running actions or would it be sufficient to assume that each action-executing system implicitly cancels actions that aren’t requested during each simulation tick? Should cancellation of actions be handled via explicit behavior tree nodes?
- Does it make sense to support deferred and persistent actions – or are deferred actions enough?
- Should actor’s be allowed to affect traversal by changes in their blackboard or should they only read a blackboard during traversal but not write to it? Would you separate the read-only and read-write part of an actor’s blackboard?
- Does it make sense to deviate from a tree structure to a directed acyclic graph (DAG) and allow sharing of whole sub-trees? If that is the case – should each path to the shared sub-tree have it’s own traversal and result state buffers or should the traversal state and behavior result states be shared, too? This would break the always forward-iteration over streams, like a loop node would, too.
To be continued – the underwood awaits you
My future articles might deviate from the behavior tree topic a bit, e.g. to dive more into parallel programming, but I’ll keep documenting the test-driven implementation of my dual – runtime and edit-time – behavior tree design. I am quite curious to see if all the theoretical advantages, e.g. more efficient memory accesses, will work out to justify the higher implementation complexity in comparison to a naive object-oriented solution. Diving into the world of web-development for a visual behavior tree editor is also something I am eager to explore – more new techniques to learn and experiment with.
Thank you so much for your time! I’m looking forward to your feedback, criticism, and questions, and would love to hear about your adventures in the mystical behavior tree forrests!
See you (hopefully) soon,
Bjoern
References
Article references
- Tony Albrecht, 2009.
- Handling Complexity in the Halo 2 AI by Damian Isla, 2005.
- Coordinating Agents with Behavior Trees by Ricard Pillosu, 2009.
- Niklas Frykholm, 2011.
- New generation of @insomniacgames tools as webapp by Chris Edwards, 2010.
- Angry Ant (Emil Johansen).
- Joacim Jacobsson .
Additional references about deferring computations and component-based game architectures for data-oriented design
- Terrance Cohen, GDC Canada 2010.
- Noel Llopis, 2011.
- Bjoern Knafla, 2009.
Behavior tree series
- Introduction to Behavior Trees
- Shocker: Naive Object-Oriented Behavior Tree Isn’t Data-Oriented
- Data-Oriented Streams Spring Behavior Trees (this post)
- Data-Oriented Behavior Tree Overview
- Behavior Tree Entrails